Search AI Products and News
Explore worldwide AI information, discover new AI opportunities
- ✓AI News
- AI Tools
2025-02-18 09:51:19.AIbase.
Mistral CEO Praises DeepSeek: A Significant Moment for Open Source AI

2025-01-29 10:33:21.AIbase.
Former Google CEO: The Rise of DeepSeek Marks a New Phase in the Global AI Competition

2025-01-25 08:59:56.AIbase.
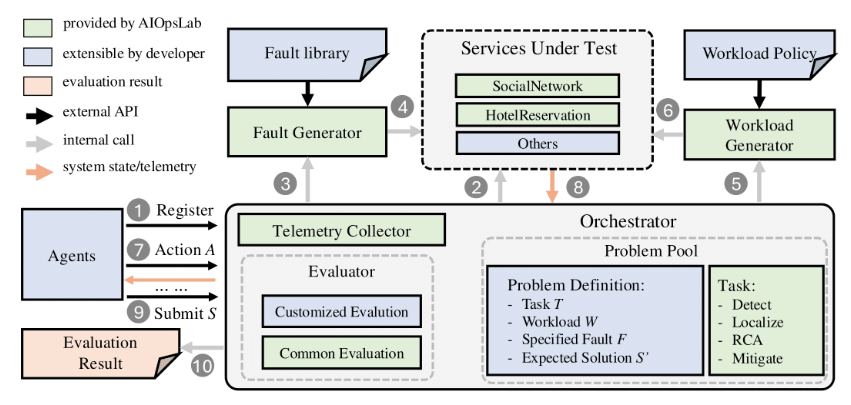
Microsoft Collaborates with Universities to Launch Open Source AIOpsLab: Enabling Autonomous Cloud AI Agents
2025-01-24 16:46:55.AIbase.
DeepSeek R1 is Coming, Meta Executives are in Panic

2025-01-03 14:32:54.AIbase.
Stanford University Open Source AI Writing System: One-Click Generation of High-Quality Long Articles, A New Breakthrough in Scientific Writing

2024-12-27 09:42:05.AIbase.
Pushing Open Source AI to New Heights: DeepSeek V3 Surpasses Llama3.1 with 14.8 Trillion Tokens of Training Data

2024-12-27 09:35:24.AIbase.
DeepSeek-V3: Release of an Ultra-Large Open Source AI Model Surpassing Llama and Qwen
2024-12-26 09:53:50.AIbase.
Deepseek V3 Now Open Source! Multilingual Programming Capability Soars, Outperforming Claude 3.5 Sonnet V2

2024-12-20 10:05:14.AIbase.
Open Source AI Assistant Pinokio Upgraded to 3.0: Custom Interface with Browser Automation

2024-12-17 16:19:16.AIbase.
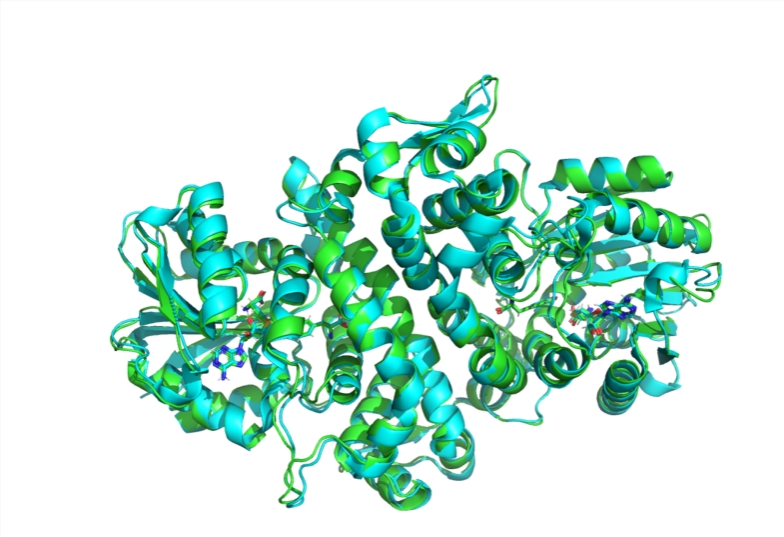
MIT Research Team Launches Open Source AI Model Boltz-1 to Advance Biomolecular Structure Prediction
2024-12-17 14:33:33.AIbase.
Meta Launches Open Source AI Try-On Model Leffa: Retaining More Details

2024-12-15 10:40:13.AIbase.
Huawei's Open Source AI Framework MindSpore to Capture 30% of China's New AI Framework Market Share by 2024

2024-12-13 10:35:45.AIbase.
Meta 'Draws the Sword'! Open Source AI Video Watermark Tool Video Seal to Combat Deepfake Proliferation

2024-11-27 14:07:42.AIbase.
Ai2 Releases New Language Model OLMo2 Competing with Meta's Llama

2024-11-21 10:47:29.AIbase.
aiOla Open Source AI Audio Transcription Model Whisper-NER for Real-time Protection of Sensitive Information

2024-11-19 09:55:29.AIbase.
NVIDIA's Open Source AI Pharmaceutical Framework Sparks Interest in the Biopharmaceutical Sector, Over 200 Institutions Compete to Adopt

2024-11-14 16:16:41.AIbase.
Open Source AI Language Model Ultravox v0.4.1: Making AI Real-Time Conversations Smoother and Smarter

2024-11-14 10:11:37.AIbase.
Exo Labs is Here! Enabling Powerful Open Source AI Models to Run Locally on Mac M4 Computers

2024-11-08 14:57:58.AIbase.
CogVideoX v1.5 Open Source AI Video Generation Model Supports 5/10 Second Video Generation

2024-11-04 09:15:45.AIbase.
